 CREMA: Generalizable and Efficient Video-Language Reasoning
CREMA: Generalizable and Efficient Video-Language Reasoning
via Multimodal Modular Fusion
Abstract
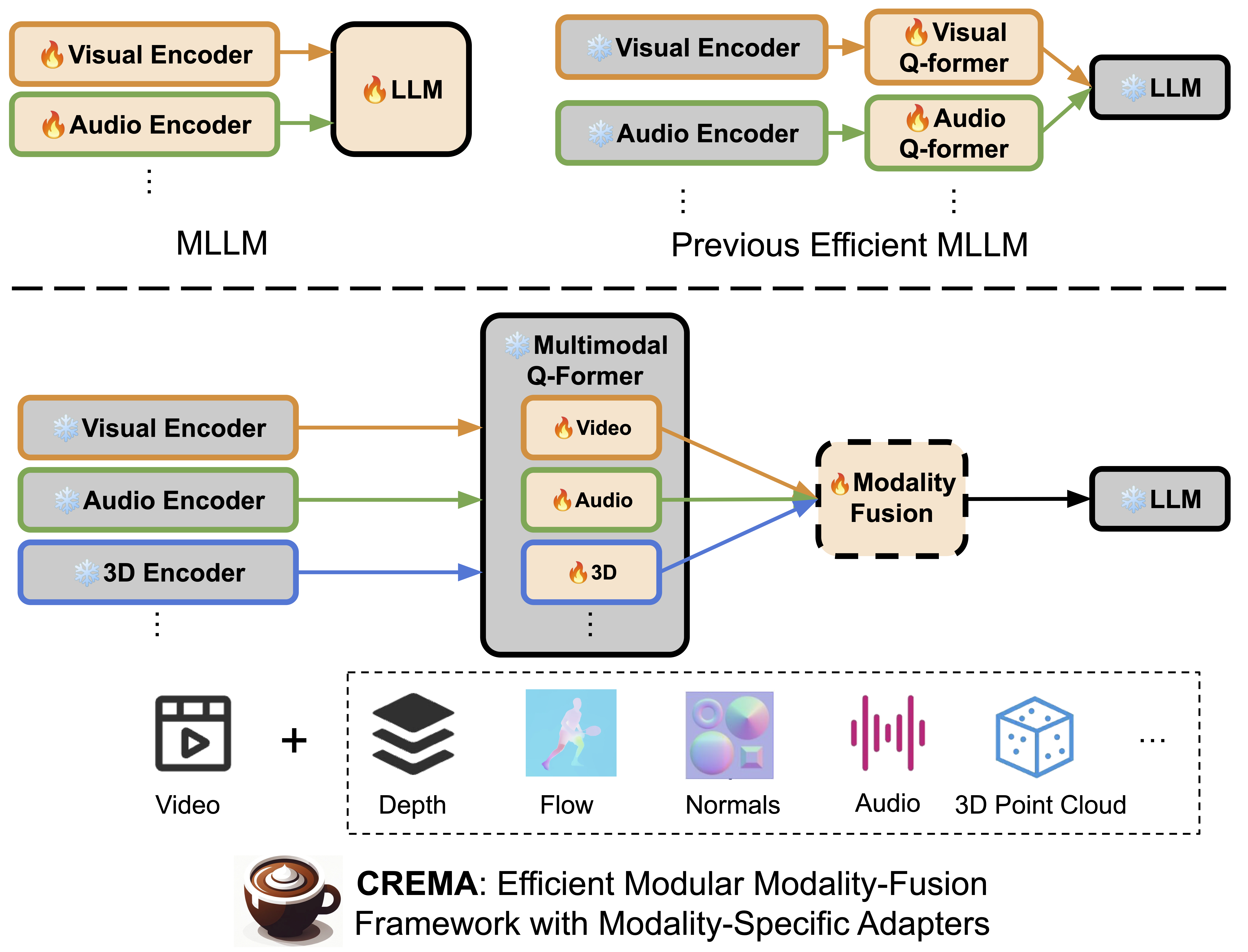
Despite impressive advancements in recent multimodal reasoning approaches, they are still limited in flexibility and efficiency, as these models typically process only a few fixed modality inputs and require updates to numerous parameters. This paper tackles these critical challenges and proposes CREMA, a generalizable, highly efficient, and modular modality-fusion framework that can incorporate any new modality to enhance video reasoning.
We first augment multiple informative modalities (such as optical flow, 3D point cloud, audio, thermal heatmap, and touch map) from given videos without extra human annotation by leveraging sensors or existing pre-trained models.
Next, we introduce a query transformer with multiple parameter-efficient modules associated with each accessible modality.
It projects diverse modality features to the LLM token embedding space, allowing the model to integrate different data types for response generation.
Furthermore, we propose a novel progressive multimodal fusion design supported by a lightweight fusion module and modality-sequential training strategy.
It helps compress information across various assisting modalities, maintaining computational efficiency in the LLM while improving performance.
We validate our method on 7 video-language reasoning tasks assisted by diverse modalities, including conventional VideoQA and Video-Audio/3D/Touch/Thermal QA, and achieve better/equivalent performance against strong multimodal LLMs, including OneLLM, BLIP-2, and SeViLA while reducing over 90% trainable parameters. We provide extensive analyses of CREMA, including the impact of each modality on reasoning domains, the design of the fusion module, and example visualizations
Results
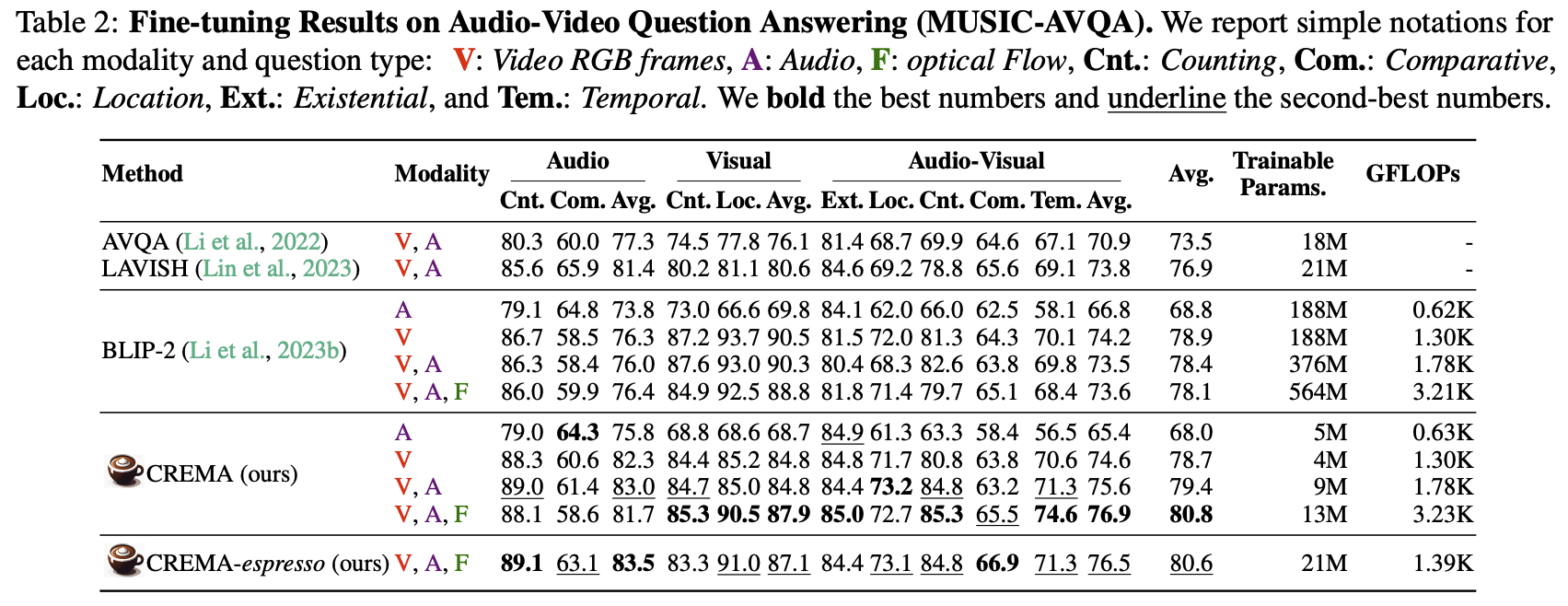
Fine-tuning Results on Video-Audio Reasoning Task (MUSIC-AVQA)
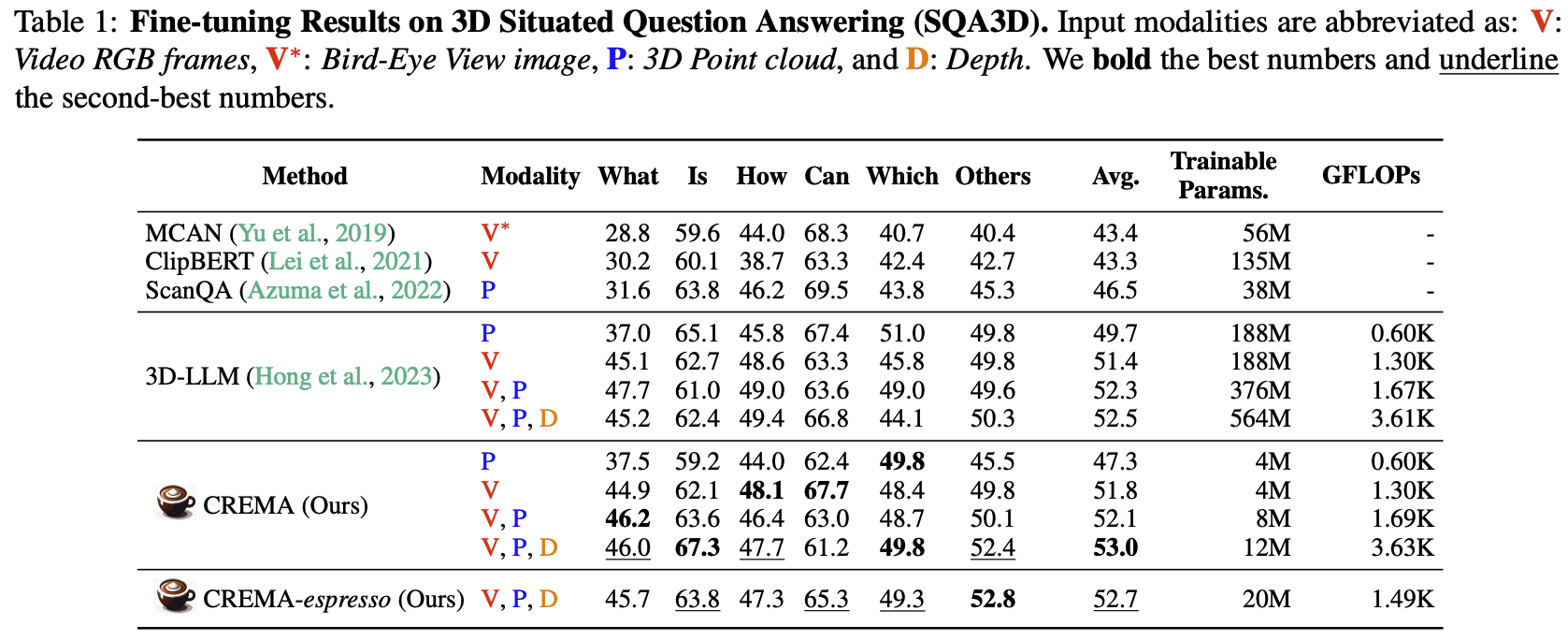
Fine-tuning Results on Video-3D Reasoning Task (SQA3D)
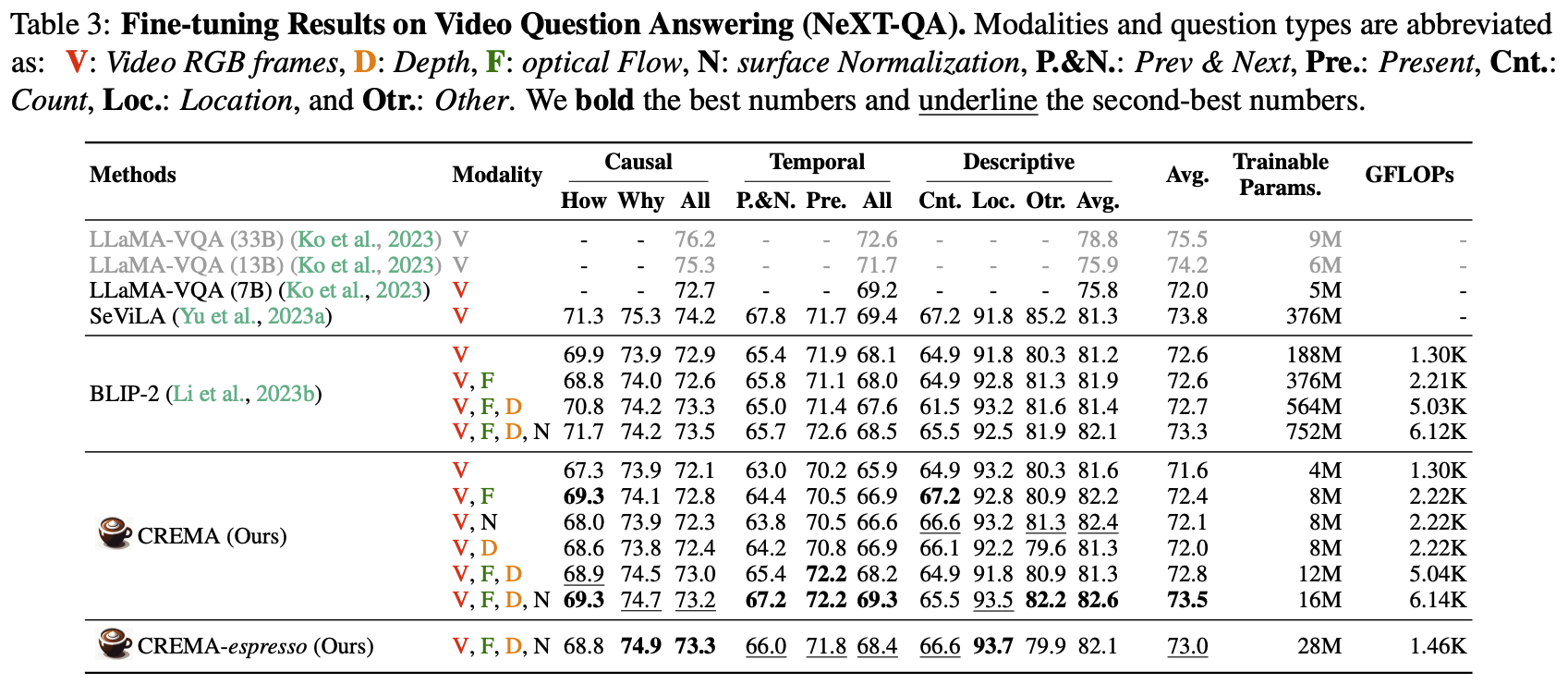
Fine-tuning Results on Video Reasoning Task (NExT-QA)
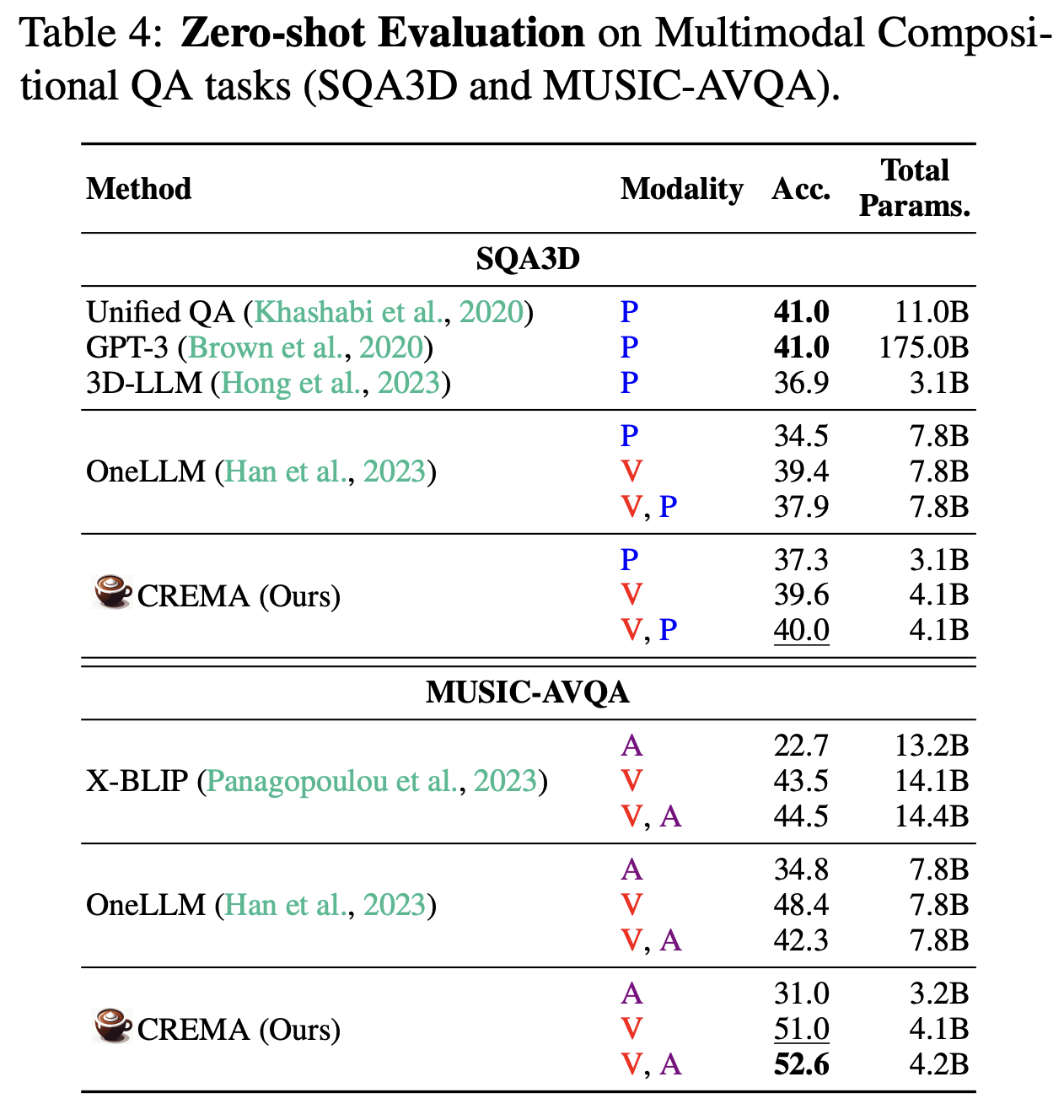
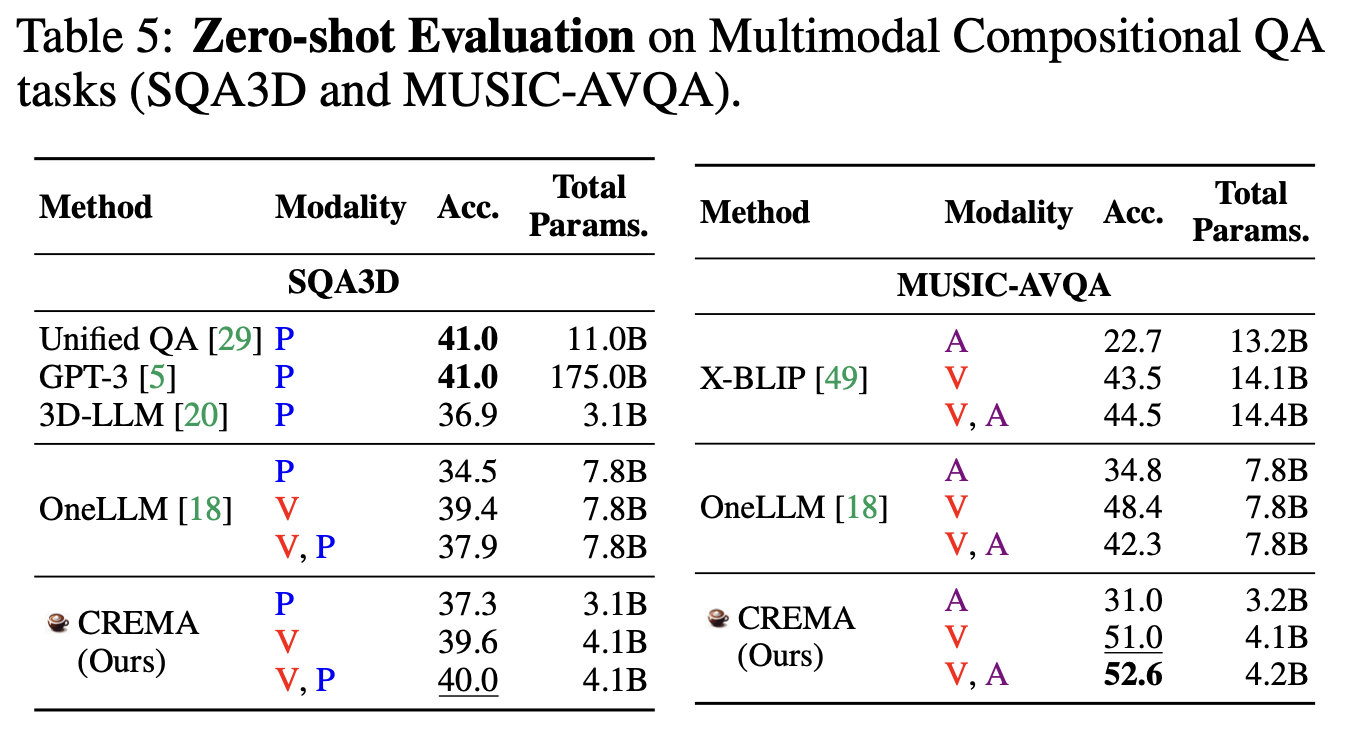
Zero-shot Evalution on Video-3D and Video-Audio Reasoning Tasks
Visualization Examples
Figure 3: Qualitative examples for multimodal compositional video reasoning from SQA3D (Left) and MUSIC-AVQA (Right). The correct predictions are marked by green check marks.
Beyond the numerical comparison of the effect integrating different sets of modalities for our CREMA method, we investigate our model's generated responses according to different types of input examples. In Figure 3 Left, CREMA with 3D point cloud inputs (P) fails to find the chair and respond to the color of the wall, brown, as its 2D scene image features are incorporated in 3D point cloud features. CREMA with Video (V) and V, P also predict inaccurate chair color, black. However, with the assistance of depth information, the method can capture objects accurately and find the designated chair as well. Similarly, in Figure 3 Right, optical flow inputs help to find musicians with their poses playing instruments, so our CREMA method can tell the middle instrument is not being played at the beginning, but from the left.
BibTeX
@article{yu2024crema,
author = {Shoubin Yu, Jaehong Yoon and Mohit Bansal},
title = {CREMA: Generalizable and Efficient Video-Language Reasoning via Multimodal Modular Fusion},
journal = {arxiv},
year = {2024},
}